
How bad data destroys AI dreams
JAN. 7, 2025
2 Min Read
Discover why flawed data strategies can derail AI projects and how to avoid common data quality pitfalls.
Data quality is the foundation of successful AI initiatives. Robust data management strategies ensure accuracy, consistency, and reliability across AI ecosystems. However, without proper data governance, the allure and promise of AI and its potential can become a harsh reality check after implementation.
5 dangerous data quality myths that impact AI success
The idea that “any data is good” in AI training is a myth; there are risks to relying on inaccurate, inconsistent, legacy, or poorly structured data sources.
Here are some common misconceptions about data usability:
- Quantity over quality: More data automatically means better AI performance.
- The truth: Data precision, relevance, and integrity matter more than sheer volume. High-quality, well-curated datasets produce superior results compared to massive, noisy collections.
- Legacy data reliability fallacy: Historical datasets are universally valid and representative.
- The truth: Legacy data can embed historical biases, outdated context, and irrelevant information. Regular validation and refreshing of datasets are crucial to maintain AI model accuracy.
- Universal data applicability error: Data from any source can be used interchangeably.
- The truth: Data sources require careful vetting. Contextual relevance, collection methodology, and potential sampling biases significantly impact AI model performance and fairness.
- Preprocessing insignificance mistake: Raw data can be directly used without extensive cleaning.
- The truth: Comprehensive data preprocessing—including handling missing values, removing duplicates, normalizing formats, and addressing outliers—is essential for creating reliable training datasets.
- Bias invisibility misconception: Data is inherently neutral and objective.
- The truth: Data often reflects societal, historical, and systemic biases. Proactive bias detection and mitigation strategies are critical to developing responsible AI systems.
Technical limitations of inconsistent data
With so many misconceptions about data, it’s easy to see how poor data governance presents significant risks to model accuracy and reliability. Inconsistent or noisy data introduces systematic errors and unreliable training datasets can skew model predictions. Meanwhile, models trained on poor-quality data generate unreliable insights which can impact decision-making.
How data inconsistencies propagate errors
Here’s a visual representation of the effects of data on models:
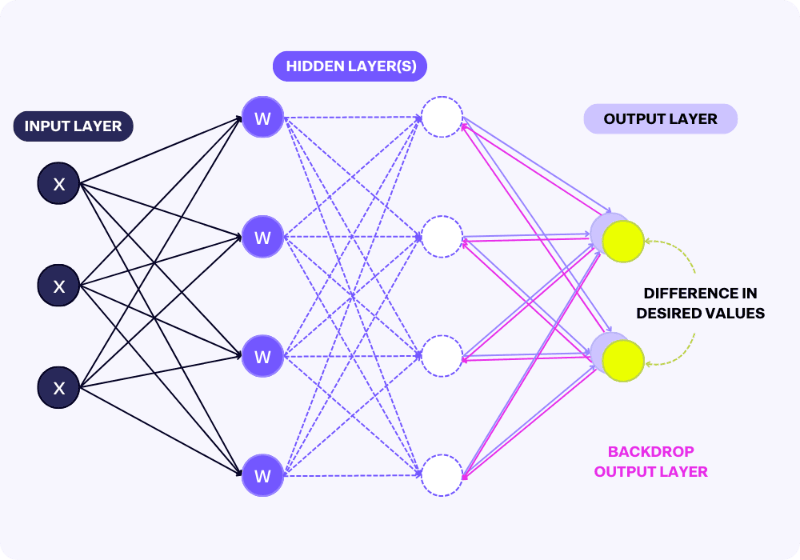
- The outputs of the model are compared against a target/desired value; the goal is to minimize the gap between the two.
- The training process involves going forward or backward until the difference in target/desired values is small.
- If the target/desired values are inaccurate or biased, the model will still try to adjust to the data.
- Any new data that comes in will be trained on this inaccurate model.
- The new data will be added to the pool of inaccurate data as a “target/desired value,” making it even more inaccurate.
This example can be seen in many generations of training on erroneous data. An AI image model produces elephants that look like this:

Scaling challenges with heterogeneous data formats
Heterogeneous data formats represent a critical complexity in modern data ecosystems. Characterized by wildly divergent data structures, sources, and representations, these formats might include:
- Structured relational databases
- Semi-structured JSON and XML files
- Unstructured text documents
- Time-series data
- Multimedia content
- IoT sensor logs
Heterogeneous data presents considerable scaling challenges for organizations, primarily through complex integration processes and interoperability barriers. Diverse data structures demand sophisticated preprocessing techniques that require flexible transformation pipelines and advanced metadata mapping to enable seamless data consolidation.
These challenges show up in increased computational overhead, latency during data preparation stages, and higher infrastructure costs. To mitigate this, engineering teams should develop robust, adaptable architectures that:
- Reconcile inconsistent schemas
- Normalize varied data formats
- Maintain performance efficiency across complex data ecosystems
- Implement intelligent data translation mechanisms
- Create abstraction layers for cross-format compatibility
The complexity of managing heterogeneous data underscores why simplistic, one-size-fits-all data approaches fail in advanced AI and machine learning contexts.
Practical constraints in AI model development
In AI model development, unstructured and diverse data sources also pose significant training challenges. Assigning random developers and hoping for the best won’t yield breakthrough innovation. For example, pulling documents from Google Docs without a clear strategy creates a data mess that would derail an entire AI project. That’s because heterogeneous data collections introduce substantial complexity when documents vary widely in format, quality, and contextual relevance and can compromise the integrity of training datasets.
Unvetted, mismatched data sources fundamentally compromise a model’s performance. Just like a world-class engineering team requires rigorous recruitment and alignment, AI needs meticulously curated, high-quality data. Dumping in poorly structured documents results in AI that’s more prone to hallucinations than reliable insights—essentially burning through your R&D budget.
Just as you wouldn't assemble a breakthrough tech team by randomly recruiting without a strategic vision, AI model development demands the same level of intentional, careful curation.
Data governance as a strategic imperative
So, what’s the answer to preventing AI models from undermining model performance and reliability? We’ve found that creating a systematic framework for data preparation ensures consistent quality, reduces the risk of introducing errors, and establishes a repeatable framework for transforming raw data into high-fidelity training inputs that accurately represent the intended learning objectives.
Here’s how to establish robust data cleaning and validating processes:
- Obtain high-quality training/test data: Data quality is foundational to AI model performance. We source clean, representative, and diverse datasets to ensure robust learning and minimize potential biases or inaccuracies.
- Incorporate data security practices: We implement encryption, access controls, and anonymization techniques to safeguard training data integrity.
- Algorithmic bias mitigation: Proactively identifying and reducing inherent biases in training data prevents AI models from perpetuating systemic prejudices. We carefully apply dataset curation, balanced representation, and statistical bias detection techniques.
- Implementation: Developing a structured, repeatable process for data preparation and model training ensures consistency and reproducibility across AI development cycles. We help standardize preprocessing, validation, and deployment workflows to optimize performance, reduce errors, and accelerate time-to-insight for AI initiatives.
- Incorporate model explainability: Enabling transparent decision-making processes enables stakeholders to understand how AI models reach specific conclusions. Implementing interpretable algorithms and visualization techniques demystifies complex AI reasoning.
- Engaging stakeholders: Collaborative input from diverse teams—including data scientists, domain experts, and ethics specialists—ensures comprehensive perspective and comprehensive risk assessment in AI model development.
- Continuous monitoring: Regular performance evaluation and data drift detection help maintain model accuracy over time. Implementing automated monitoring systems enables rapid identification and correction of potential degradation or emerging biases.
Improving data integrity for AI modeling
Here’s how to establish a comprehensive, dynamic approach to maintaining high-quality, reliable data for AI model development:
1. Create data validation frameworks
- Implement automated checks for data quality.
- Detect inconsistencies, anomalies, and potential biases.
- Ensure data meets predefined accuracy and reliability standards.
2. Standardize data ingestion protocols
- Create uniform data input processes.
- Define consistent data format and metadata requirements.
- Minimize manual intervention and reduce human error.
3. Automate data quality monitoring
- Use real-time tracking for data integrity.
- Perform continuous performance assessment of data pipelines.
- Proactively identify and resolve data quality issues.
4. Adapt your data transformation architectures
- Leverage modular design supporting multiple data formats.
- Apply adaptable preprocessing and normalization techniques.
- Scale your infrastructure as your data ecosystem evolves.
A competitive advantage
Data integrity isn’t a technical checkbox—it’s a strategic differentiator. Viewing data infrastructure as a critical investment will help businesses outpace competitors by building AI systems that are not just technologically advanced, but fundamentally reliable, ethical, and precise.
In the end, AI’s potential is directly proportional to the quality of the data. By prioritizing robust data cleaning, continuous validation, and a systematic approach to data preparation, an organization can transform data from a potential liability into its most strategic asset.



