
MAR. 6, 2025
3 Min Read
How it started
I recently read about a cyclist who always missed out on doughnuts at café stops because he was a bit slower than the rest of the group. His solution? He built a simple app that checked his location and ordered doughnuts when he was 20 minutes away. I wanted to take that idea further.
A few years ago, I was diagnosed with Type 1 Diabetes. My body no longer produces insulin, requiring artificial supplementation through injections. The constant insulin-after-eating roller coaster drove me crazy, leading me to discover cycling to burn excess glucose while enjoying occasional sweet treats during rides.
As an avid cyclist, I’ve found myself 60 miles into a 100-mile gravel ride before realizing I was down to my last snack. With my blood sugar dropping at an alarming rate, I’d be stuck in the middle of nowhere—on a fire road, resembling something from the Texas Chainsaw Massacre. It was time to build a solution.
The project goal
Blood sugar is complex, and influenced by countless factors. That's why I wear a Continuous Glucose Monitor (CGM) that streams data to my Garmin. I typically burn through 20g of carbs every 20-30 minutes of cycling but often eat too little, too late, resulting in a weird game of catch-up.
So I created a service that predicts when my blood sugar will drop and finds a store within range based on my speed and route, provides directions, and orders something that will be ready when I arrive.
The building blocks: Integrating standard code and AI
By applying a smart architecture, I can leverage existing technologies while focusing AI development where it truly adds value.
Here’s the component breakdown:
- Get Garmin live data to an API: Garmin’s LiveTrack feature already provides accessible real-time riding data through their standard endpoints.
- Predict a blood sugar drop based on Garmin data: This is where machine learning shines–I’ll evaluate several predictive models trained on my historical ride data to find the optimal approach.
- Find a nearby restaurant and order something: Third-party APIs from Google, Uber, and others handle the logistics, while an LLM can personalize food selection based on my specific nutritional needs.
Based on the list above, the only AI-driven components needed are blood sugar prediction and food selection. Most of the rest can be handled through standard tasks.
Data, data, data
Accurately predicting blood sugar drops during rides is essential. For this, I followed CRISP-DM (Cross Industry Standard Process for Data Mining). As William Vorhies notes, this framework “provides strong guidance for even the most advanced of today's data science activities.”
CRISP-DM breaks down into six key phases:
- Business understanding: Define project goals from a business perspective, understand the problem, and define project objectives.
- Data understanding: Collect initial data and explore it to identify patterns, quality issues, and the structure to guide further steps.
- Data preparation: Clean and transform data, selecting and organizing it into a usable form for modeling.
- Modeling: Use various modeling techniques to create predictive or descriptive models.
- Evaluation: Assess model quality and performance against project objectives to ensure it meets business needs.
- Deployment: Implement the model in a real environment, sharing results and setting up systems for ongoing use.
My data sources
I’m a gadget person. I use a CGM, heart rate monitor, and Edge cycling computer that all feed into Garmin Connect. While Connect doesn’t have a “download all” button for ride data, its web interface displays everything I need in one place. With some web scraping magic, I can pull comprehensive datasets that show trends throughout my rides, capturing the metrics displayed in those helpful graphs.
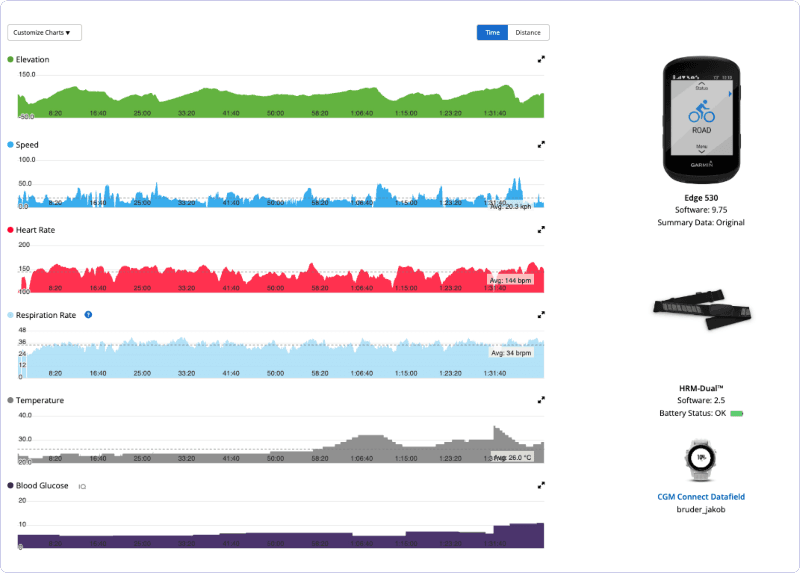

 Now I’ll prepare the data to make meaningful predictions. Good feature engineering transforms raw measurements into patterns a model can learn from.
Now I’ll prepare the data to make meaningful predictions. Good feature engineering transforms raw measurements into patterns a model can learn from.
